Материалы по тегу: moore threads
|
30.12.2024 [15:26], Сергей Карасёв
Китайский ускоритель Moore Threads MTT X300 обеспечивает FP32-быстродействие до 14,4 ТфлопсКитайская компания Moore Threads, по сообщению ресурса TechPowerUp, подготовила к выпуску профессиональный GPU-ускоритель MTT X300. Изделие предназначено для работы с системами автоматизированного проектирования (CAD), платформами информационного моделирования зданий и сооружений (BIM), видеоредакторами и пр. Новинка выполнена в виде двухслотовой карты расширения с интерфейсом PCIe 5.0 x16. В основе лежит архитектура MUSA второго поколения с 4096 ядрами MUSA и 16 Гбайт памяти GDDR6 с 256-бит шиной (пропускная способность достигает 448 Гбайт/с). Производительность на операциях ИИ в режиме FP32 составляет до 14,4 Тфлопс. Показатель TDP равен 255 Вт. 
Источник изображения: Moore Threads @Olrak29_ on X Ускоритель оснащён тремя разъёмами DisplayPort 1.4a и одним коннектором HDMI 2.1 с возможностью вывода изображения одновременно на четыре монитора. Поддерживается разрешение до 7680 × 4320 пикселей (8К). Реализовано аппаратное ускорение при декодировании материалов AV1, H.264, H.265, VP8, VP9, AVS, AVS2, MPEG4 и MPEG2, а также при кодировании видео AV1, H.264 и H.265. Устройство поддерживает до 36 параллельных потоков 1080p (30 кадров в секунду) как для декодирования, так и для кодирования. Подчёркивается, что Moore Threads разработала для MTT X300 драйверы, обеспечивающие совместимость со всеми распространёнными архитектурами CPU, включая x86, Arm и LoongArch. 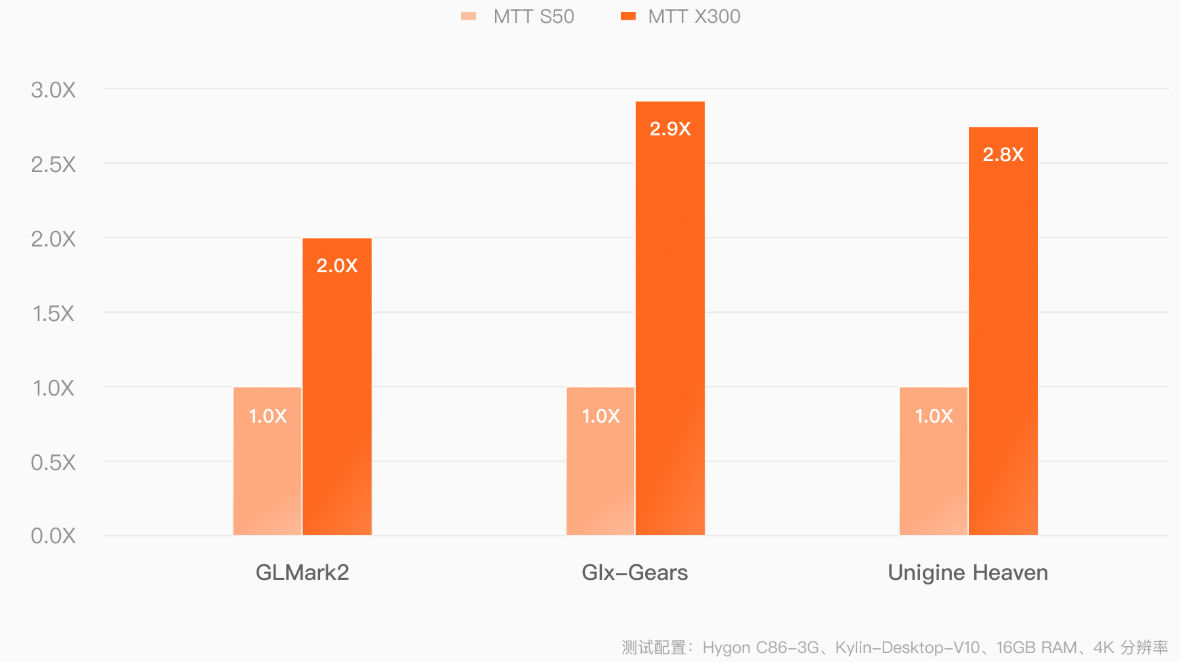
Источник: Moore Threads Нужно отметить, что ещё год назад Moore Threads представила ускоритель MTT S4000 на архитектуре MUSA третьего поколения с 48 Гбайт памяти GDDR6 с пропускной способностью до 768 Гбайт/с. Это решение демонстрирует производительность до 25 Тфлопс на операциях FP32, до 50 Тфлопс на операциях TF32, до 100 Тфлопс на операциях FP16/BF16 и 200 TOPS на операциях INT8. Карта способна обрабатывать одновременно до 96 видеопотоков 1080p.
20.12.2023 [17:00], Сергей Карасёв
Представлен китайский ИИ-ускоритель Moore Threads MTT S4000 с быстродействием до 200 TOPSКитайская компания Moore Threads, по сообщению ресурса VideoCardz, анонсировала специализированный ускоритель MTT S4000 для приложений ИИ и работы с большими языковыми моделями (LLM). Решение выполнено в виде двухслотовой карты расширения с интерфейсом PCIe 5.0 х16. В основу изделия положена архитектура MUSA третьего поколения, подробности о которой не раскрываются. Есть 48 Гбайт памяти GDDR6 с пропускной способностью до 768 Гбайт/с. Реализована технология MTLink 1.0, которая позволяет объединять в одной системе несколько ИИ-ускорителей. 
Источник изображений: Moore Threads Как утверждает Moore Threads, новинка обладает производительностью до 25 Тфлопс на операциях FP32, до 50 Тфлопс на операциях TF32, до 100 Тфлопс на операциях FP16/BF16 и 200 TOPS на операциях INT8. Для сравнения: ИИ-ускоритель предыдущего поколения MTT S3000 несёт на борту 32 Гбайт памяти и обеспечивает пиковую производительность FP32 на уровне 15,2 Тфлопс. Таким образом, размер памяти увеличен на 50 %, тогда как быстродействие FP32 поднялось на 64 %. Изделие MTT S4000 оснащено пассивным охлаждением. Предусмотрены четыре разъёма DisplayPort, что позволяет подключать мониторы. Заявлена возможность одновременной обработки до 96 видеопотоков в формате 1080p. Сопутствующие инструменты разработки USIFY позволяют полноценно использовать программное обеспечение NVIDIA на базе CUDA.  Ускорители Moore Threads MTT S4000 будут поставляться по отдельности и в составе систем Kuae, аналогичных NVIDIA DGX. Платформа Kuae MCCX D800 содержит восемь карт; возможно объединение таких серверов в кластеры. Говорится о поддержке различных LLM, таких как LLaMA, GLM, Aquila, Baichuan, GPT, Bloom, Yuyan объёмом до 130 млрд параметров. Первые 1000 ускорителей MTT S4000 лягут в основу нового китайского кластера для ИИ-задач. Moore Threads отмечает, что китайский исследовательский институт Чжиюань посредством кластера с 1000 ускорителей смог обучить модель с 70 млрд параметров за 33 дня, тогда как для 130 млрд параметров потребуется 56 суток. |
|

